This article shows how to use the Encog Machine Learning Framework for determining the Credit Rating of a Country using an Artificial Neuronal Network (ANN)[1]This rating method was mainly described by Wikirating user MovGP0.
Prerequisites
- An Application for editing .csv Files.
- A Textprocessor application might be good enough, but a Spreadsheet Application like Apache OpenOffice Calc or Microsoft Office Excel is recommended.
- The Encog Workbench from Heaton Research
- Download the newest version of the workbench[2]Check https://github.com/encog/encog-java-core/downloads (ie. encog-workbench-3.1.0-release.zip).
- Unzip the Archive and start the “encog-workbench-3.1.0-executable.jar”.
- If its not working, you might need to install the Java Runtime Environment (JRE) first.
Prepare Training Data
The first (and most time consuming) step is to gather data and bring it into an fitting format.
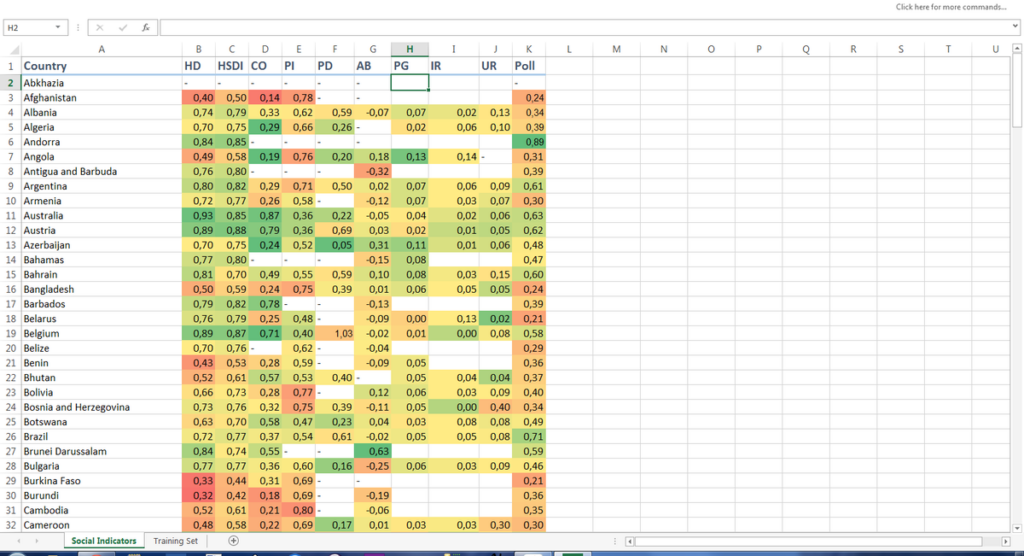
-
Gathering data in an spreadsheet document.
From the spreadsheet you select the countries where you have enough data about. Then you copy that data (without the country name) into a new spreadsheet and save it as a Comma Separated Values (*.csv) file.
Woking with Comma Separated Values
Open the .csv in an text editor and make sure that the result looks something like the following:
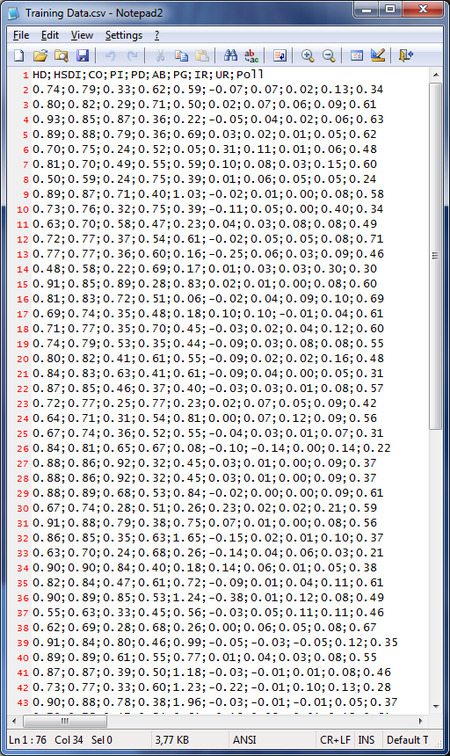
HD;HSDI;CO;PI;PD;AB;PG;IR;UR;Poll 0.74;0.79;0.33;0.62;0.59;-0.07;0.07;0.02;0.13;0.34 0.80;0.82;0.29;0.71;0.50;0.02;0.07;0.06;0.09;0.61 0.93;0.85;0.87;0.36;0.22;-0.05;0.04;0.02;0.06;0.63 ...
Plese see CSV:basic rules and examples for other possible data formats. You can also use other characters for delimiting the values and commas, skip the header line, or write the values in “”-Marks as in the following example:
"HD","HSDI","CO","PI","PD","AB","PG","IR","UR","Poll" "0.74","0.79","0.33","0.62","0.59","-0.07","0.07","0.02","0.13","0.34" "0.80","0.82","0.29","0.71","0.50","0.02","0.07","0.06","0.09","0.61" "0.93","0.85","0.87","0.36","0.22","-0.05","0.04","0.02","0.06","0.63" ...
Each row represents a specific country, while each column represents an economic indicator. The last column contains example results that the ANN should produce when given the specific indicators. In this case we use the results from the User Polling, since it produces the most accurate results[1], but you can also use other ratings.
The first line are the table headers, so you know what the values are for. Then follows a list of numeric values, where each line represents a specific country. Note that we have removed the country name from the table. Please make sure that your numeric data does not contain characters like ‘%’, ‘#’, dates or other data that is not a numeric value.
Handling incomplete Data
If you do not have a complete dataset for a specific country, than you can use that too. Encog is able to fill out the gaps by using interpolating methods. It increases the training for the ANN, but will also make the training less stable, since the ANN will train on false data. You should leave incomplete records out. As a general rule there should not missing more than a single indicator for a specific country. Further, you might want to use older data if current data is missing.
Incomplete data might look like the following (notice the gaps indicated by ;;):
0.67;0.74;0.36;0.52;0.55;-0.04;;0.01;0.07;0.31 0.84;0.81;0.65;0.67;;-0.10;-0.14;0.00;0.14;0.22
You can only use records where you have at least an existing rating. Do not use another indicator or another rating to replace a missing value. In example, the following records are not useable:
0.67;0.74;;0.52;0.55;-0.04;;;;0.07;0.31 -- to many values are missing 0.84;0.81;0.65;0.67;;-0.10;-0.14;0.00;0.14; -- the rating (last column) is missing
The best way to handle gaps is to search on the internet for a better data source to fill them with correct data.
Using the Encog Workbench
If the training data is prepared you open the Encog Workbench. It should show the following dialog:
Select “New Project Folder…”
Give the Project a new Name and select “OK”. Now you see the Workbench:
Drag & Drop your .csv file into the Workbench.
Select “Yes” to import the data into the project.
Rightclick the data file and select the “Analyst Wizard…”
Using the Analyst Wizard
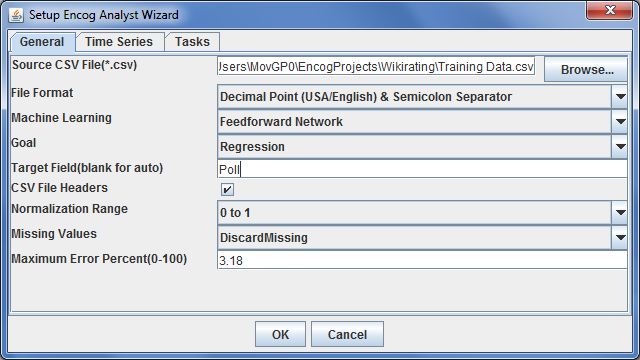
Make the settings as described here:
| Setting | Description |
|---|---|
| File Format | Select the format in which your .csv file is. You need to select the decimal point and the separating character. Note that only specific combinations are allowed. If your file does not match open it in a text editor and use find/replace to correct the format. |
| Machine Learning | Keep the “Feedforward Network” settings. |
| Goal | Change to “Regression” since we want to have a single outgoing rating value (default). (Note: You might want to use the classification setting when you have a list of possible ratings and the network should decide which one is the correct one.) |
| Target Field | Insert the name of the column containing your example ratings. (while this is recommended, you only need to do this if its not the last one). |
| Normalization Range | Select “0 to 1” to get the result as a rating value between 0 and 100%. |
| Missing Values | Here you can select how Encog should handle missing values. You should select “DiscardMissing”, except your data is mostly complete and only very vew values are missing. |
| Maximum Error | Select the Precision that is needed to stop the training of the ANN. If you select an error that is too high (ie. >5%), the results you get from the ANN are not meaningful. If you select an error that is too low, then the training will not stop unless you stop it. Since the error is strongly depended on the training data and training method, you might need an trial-and-error approach to enter a proper value. |
You can leave the other values at default and select “OK”. The wizard generates an .ega file that contains statistical information about your training data.
Visualization of Training Data
You can visualize the statistical information of the .ega file by clicking on Visualize, select the proper Visualisation and click “OK”. This might give you some insight into the data you are working with.
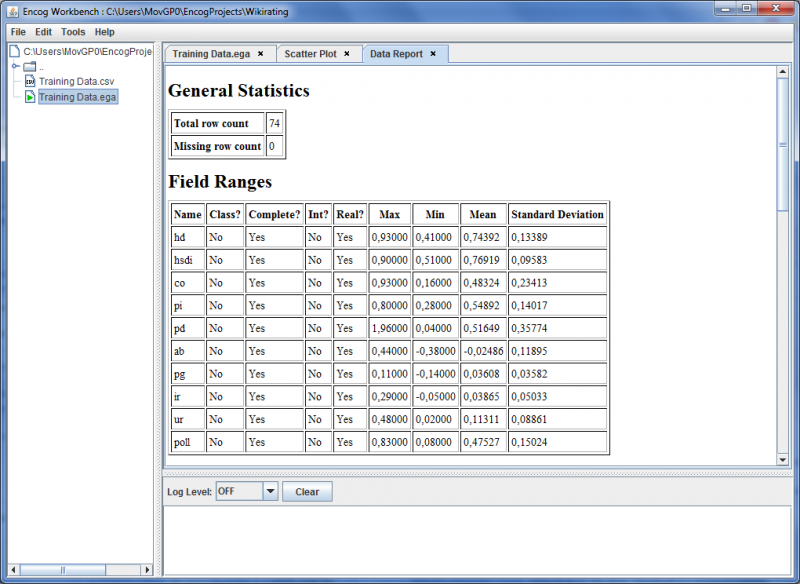
The Data Report provides statistical information, such as minimal and maximal values and standard Derivation. This information is needed to normalize the data for the training of the ANN.
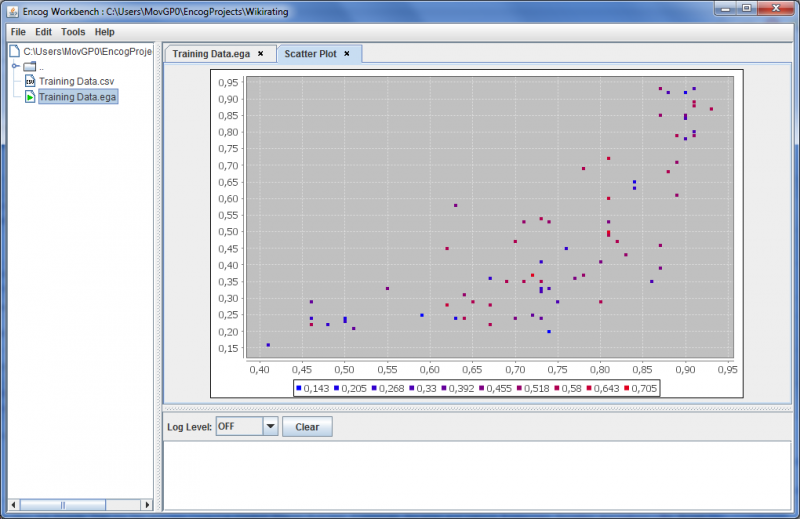
The Scatter Plot allows to relate different indicators to see if there is a correlation. In the example here, there is an exponential correlation between the Human Development Index and the Index of perceived corruption.
Executing the .ega File
When you have the .ega File open, click on “Execute” while keeping the setting on “task-full”.
Now click on “Start”.
You can now close the Analyst and the .ega file.
As you can see on the left, Encog Workbench has created different files. The .csv files is the data that is normed and randomized for training purposes. Then the Workbench has created a binary version of the data (.egb) that is faster to process.
- Note: If you have data that is not actual or is missing some values, you might want to open the .egb file and reduce the significance of those specific data rows. This might be tricky to do, because the data is now normalized, so you have to count the lines to find the correct one. After making changes you will have to retrain the network.
Handling the Artificial Neural Network
Inspecting the ANN
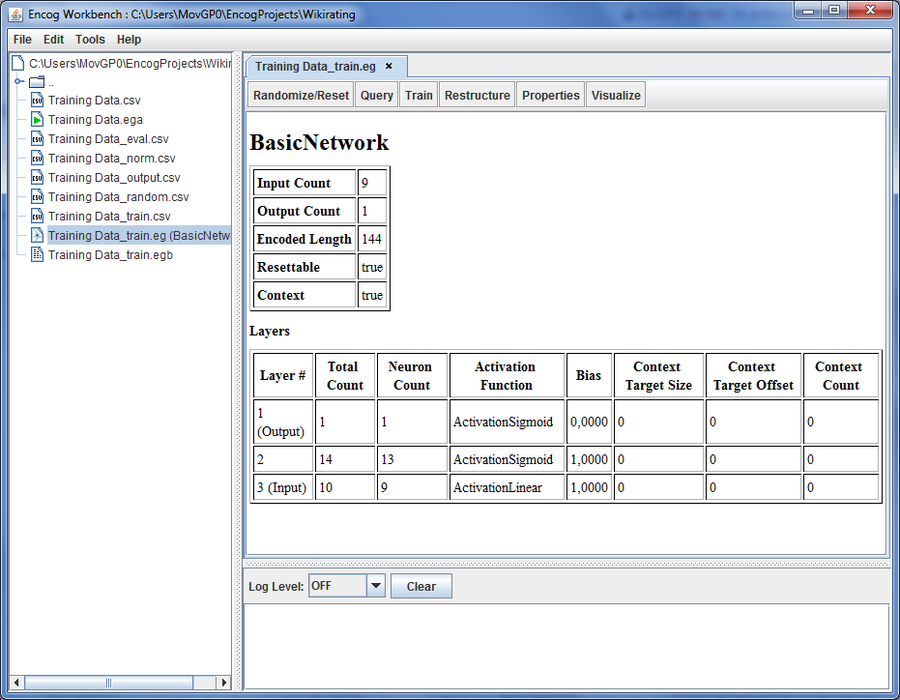
On the left you have a .eg file that represents the neural network[2]. If you open it you can get some basic information about how it is built.
As you can see, there are 9 Neurons that take the input (one for every row in the data). The 9 input neurons connect to a Hidden Layer of 13 Neurons with an sigmoid function response. The result of the calculation will be collected in a single output neuron that puts out the rating. If you want to see that more clearly, you can visalize it by clicking the “Visualize” button and then select “Network structure” from the list and click “OK”.
You can now see the structure of the Neural Netwok:
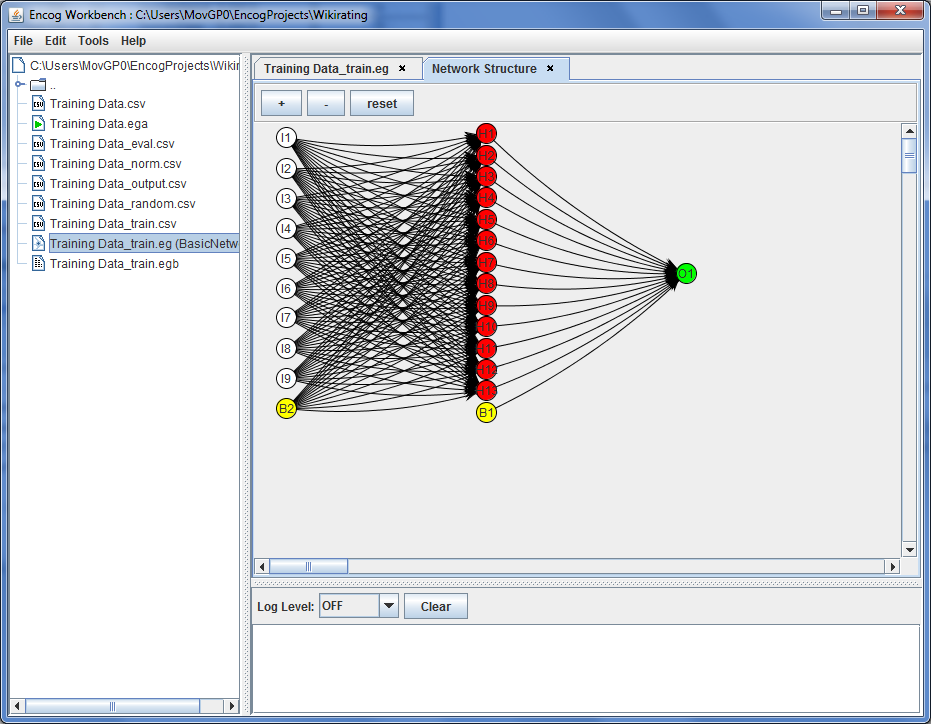
The two bias neurons B1 and B2 are just a constant providing a 1 value, so that the output of the neurons can reach a bigger value. Each line that connects the neuron of one layer to another is a weighting-function, which is basically a multiplication with a constant value. The exact value is determined by the training algorithm.
Training the ANN
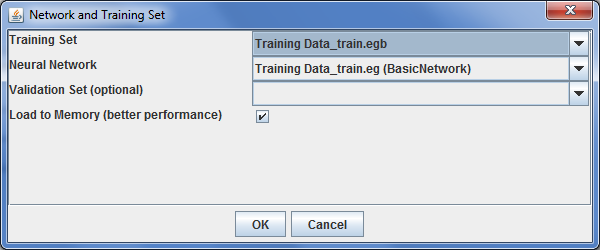
If you have the Network open, you can train the Network by pressing the Train button.
You can now select the training data. Since there is probably only one file, the correct one is already selected. However, you might want to provide additional data files with some additional data (that is data from additional countries or data from another year) to verify if the resulting network works correct with new data.
Now click on “OK” to get different training methods.

Select the training Method that works best (usually you determine that by trial-and-error to find the method that results in the lowest error at the fastest pace). We use “Resilient Propagation” for this example, because its a fast algorithm and we have only a simple neural network, and confirm with “OK”. Depended on the algorithm you will get additional settings for the boundaries of the optimization. Most importantly the error when the optimization of the network should stop. A higher value will result in a less precise working network. A value that is to low will lead to a training that does not stop unless you stop it manually.
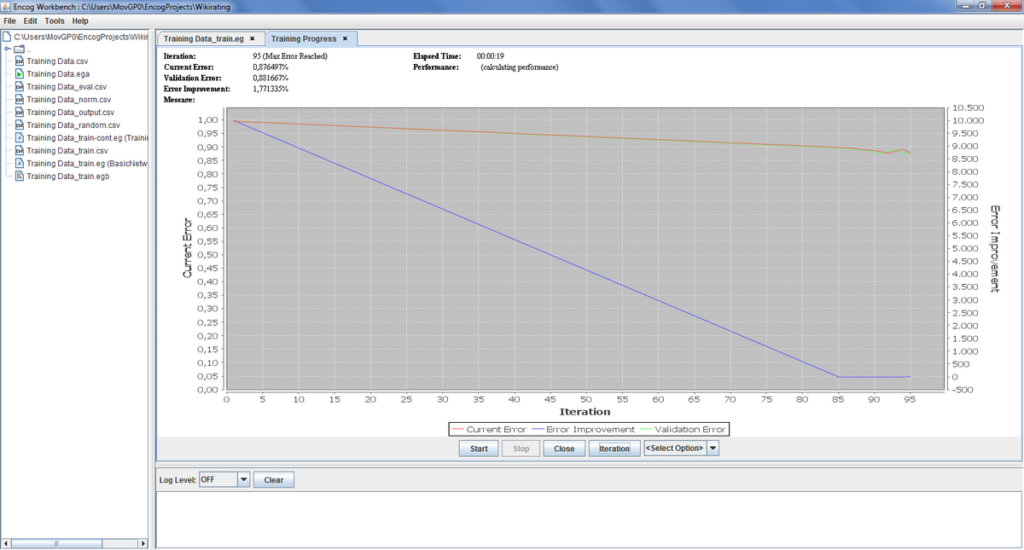
As you can see on the blue line, the training came to a point where further training with the given data will not improve the error of the network. The red and green lines indicate that the error that the network produces is now below 0.9% and thus good enough for our purposes. If you have provided additional data, the green line will indicate how well the network will behave with new and unknown data. You can now select “Close” and “Yes” to save the trained weights for the network.
Using the ANN
To use the ANN, we need to click on “Query”. Now we select “Regression”, since its a Network that calculates a single output (the rating) rather than a classification network.
Select “OK” to get the Query view.
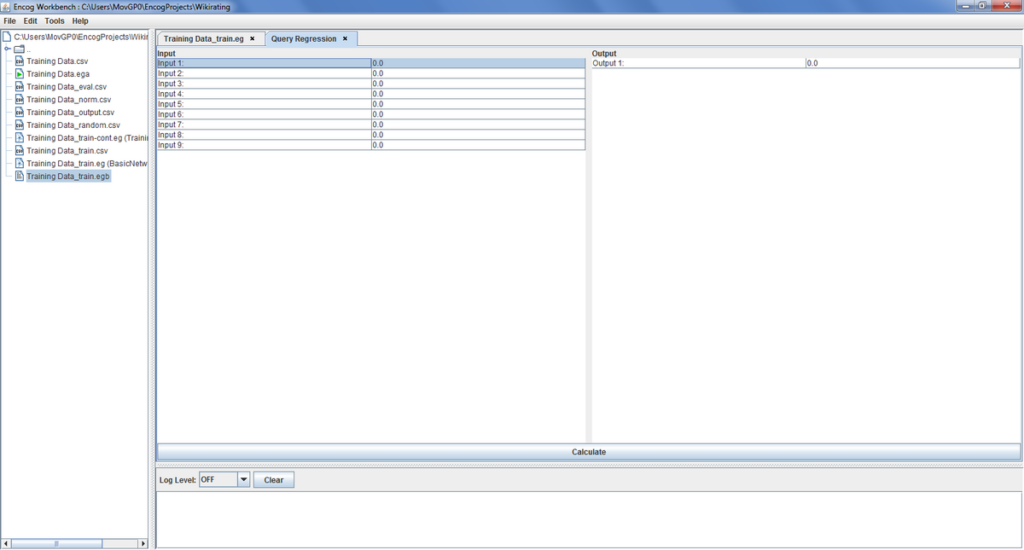
You can now enter the data for a new country. Please make sure that the input is normalized properly and written in the correct column, because the network will generate a false result otherwise.
Advantages and Disadvantages
The advantage to using ANN’s is that they are capable of solving very complex multidimensional linear equations. Given enough training data (that do not lack major information that humans have) and examples how humans would rate a country based on the available data, the ANN provides ratings that are almost as good than the ratings of the users. A well trained ANN represents the best possible rating formula.
The calculation result of an ANN is unstable and produces false results when not enough, too incomplete, or too flawed data was used for training. The specific ANN produced by training also varies strongly on the training data and the used training algorithm, which makes it hard to reproduce an ANN. The calculations are usually not transparent and not understandable for humans, since it involves the solution of multidimensional linear equations.
Literature
- James Surowiecki (2004), The Wisdom of Crowds: Why the Many Are Smarter Than the Few and How Collective Wisdom Shapes Business, Economies, Societies and Nations, Economies, Societies and Nations Little, Brown ISBN 0316861731
- http://www.heatonresearch.com/wiki/BasicNetwork_EG_File
- Jeff Heaton (2011), Introduction to the Math of Neural Networks, ISBN 9781604390339
Appendix
- Example Training Data
- (copy the first line and move a part of this file to create a second .csv file with test data)
See also
- Sovereign Wikirating Index for data on the most common economic indicators.
References